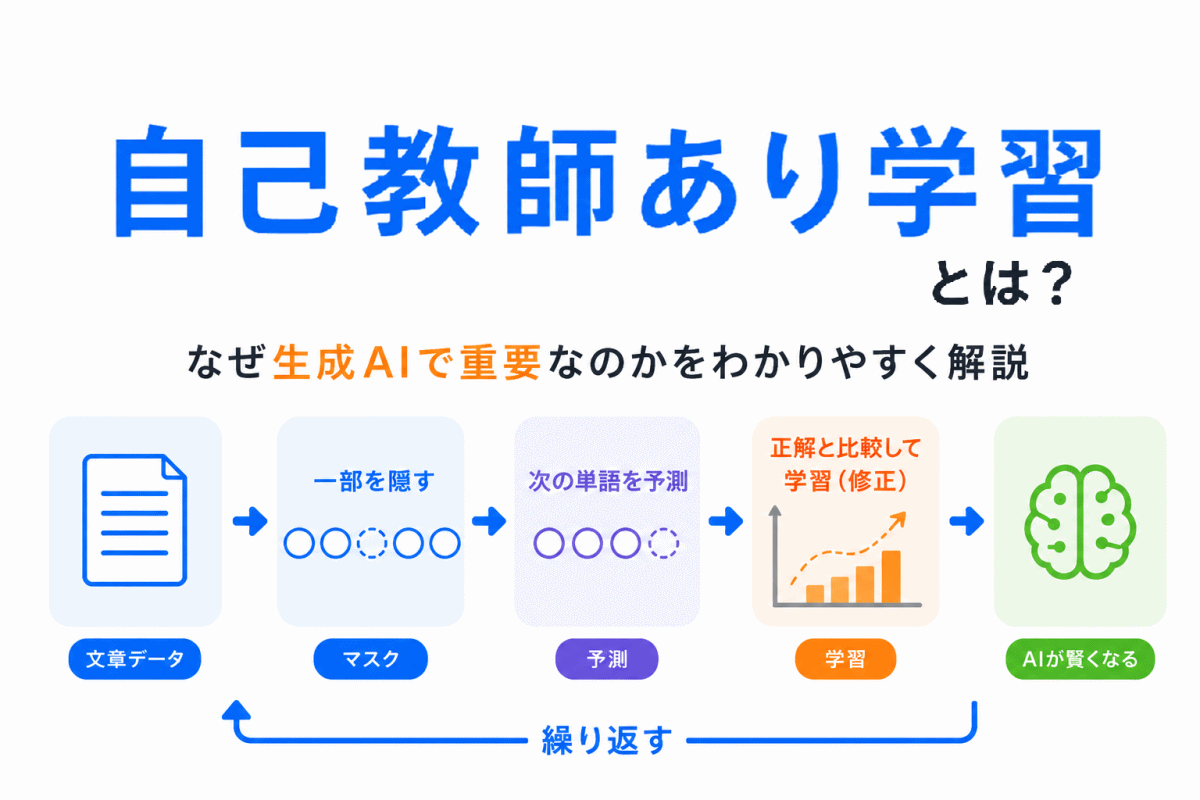
【G検定対策】自己教師あり学習とは?|なぜ生成AIで重要なのか
seo-webmaster
G検定対策ブログ
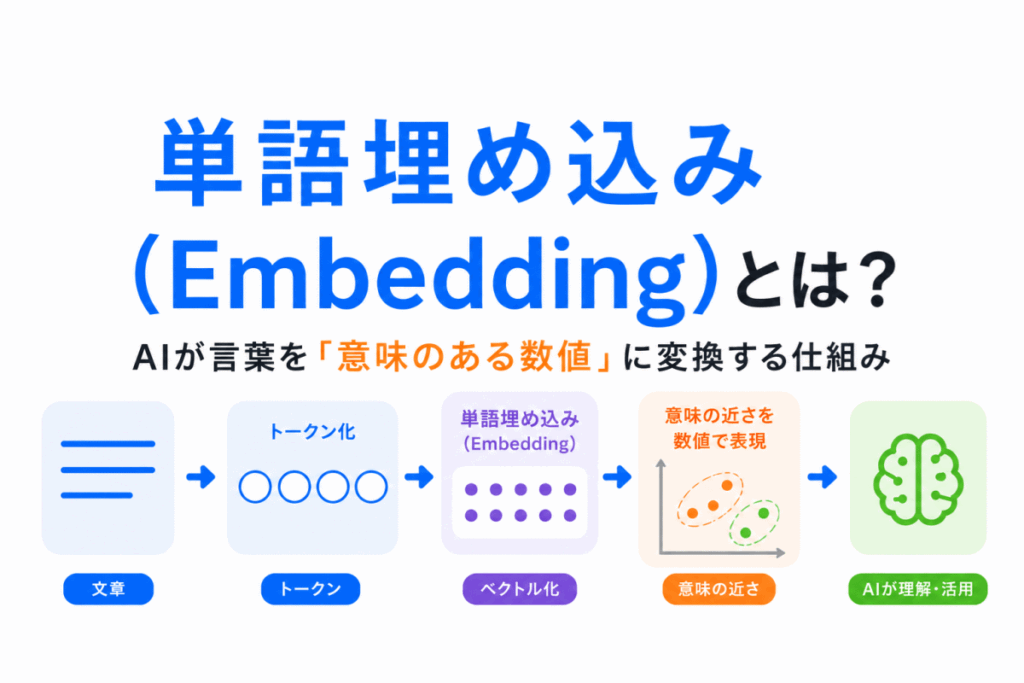
単語埋め込み(Embedding)は、生成AIや自然言語処理を理解する上で非常に重要な技術です。
「分散表現」、「word2vec」、「one-hot表現」などと関連して登場しやすく、近年ではTransformer・GPT・RAGの理解にも深くつながっています。
しかし、「単語を数値化する」と言われても、なぜ必要なのかイメージしにくい人も多いと思います。実際には、AIは文字をそのまま理解しているわけではなく、「意味を持つ数値」として処理しています。
この記事では、単語埋め込みとは何かを、AI内部の流れを見ながらわかりやすく整理していきます。
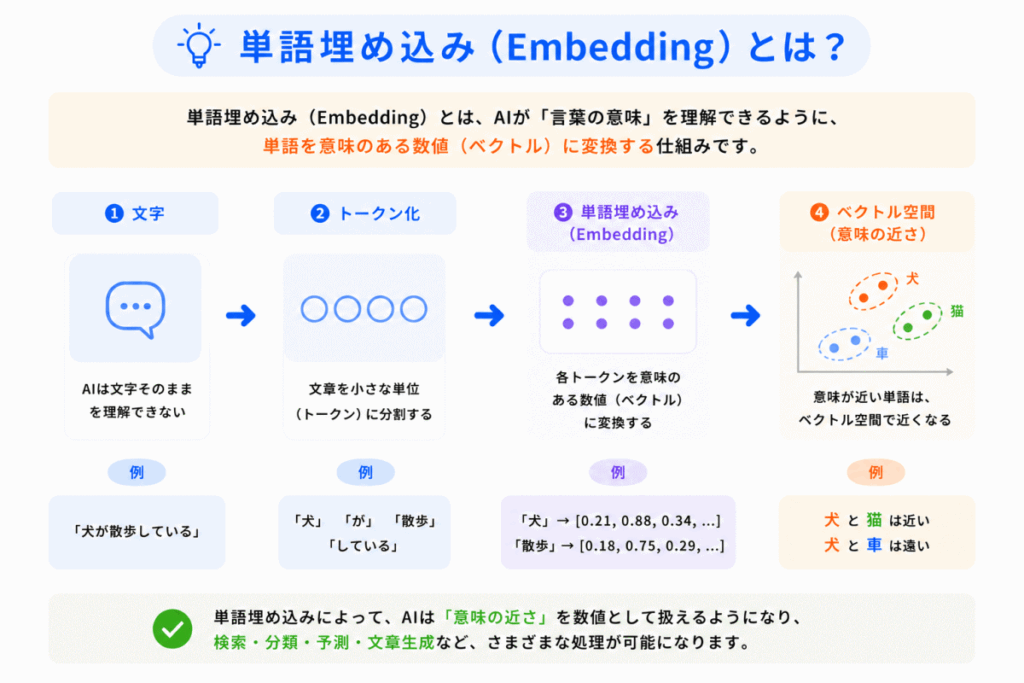
単語埋め込み(Embedding)とは「単語を意味のある数値(ベクトル)へ変換する技術」です。
AIは、人間のように文字そのものを理解しているわけではありません。
そのため、文章をそのまま扱うことができません。
そこでAIは
という流れで処理します。
つまり「AIが言葉を理解できる形へ変換する」のが単語埋め込みです。
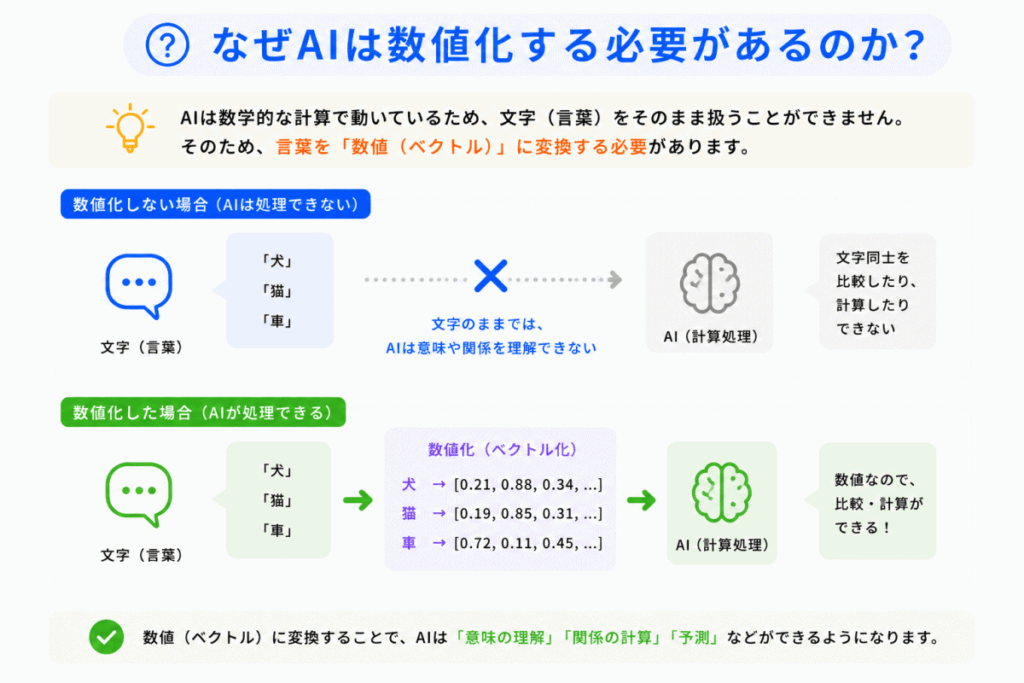
AIは数学的な計算で動いています。
そのため
のような文字列を、そのまま比較できません。
そこで「言葉を数値へ変換」します。
例えば
のように変換します。
ここで重要なのは「意味が近い単語は、近い数値になる」ことです。
つまり
という関係を、AIが数値として扱えるようになります。
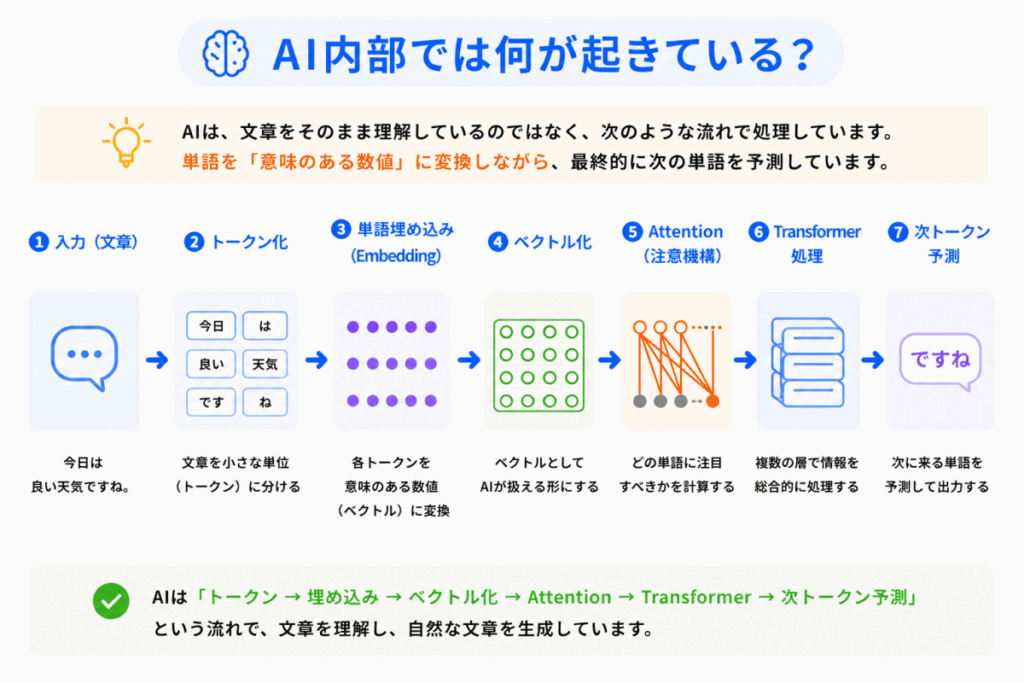
AI内部では、次のような流れが起きています。
ここで重要なのが「文字のままではなく、意味を持つ数値として扱う」という点です。
GPTやTransformerも、最終的には「ベクトル計算」で動いています。
つまり単語埋め込みは「生成AIの入口」とも言える重要技術です。
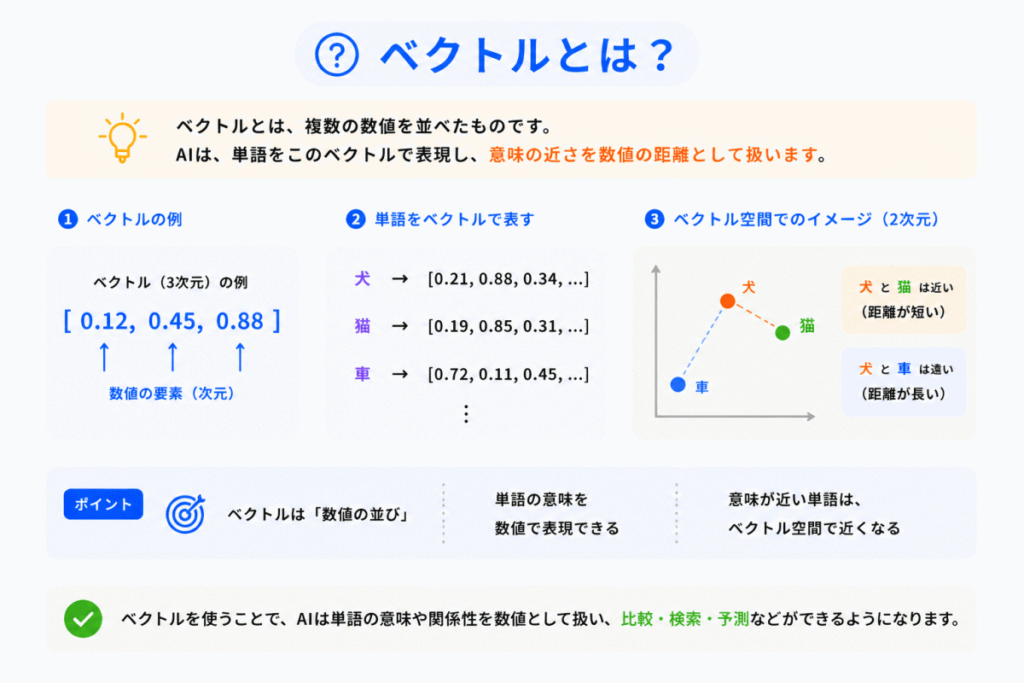
ベクトルとは「複数の数値を並べたもの」です。
例えば
[0.12, 0.45, 0.88]
のような形です。
単語埋め込みでは「単語の特徴」を、このベクトルで表現します。
例えば
は近いベクトルになります。
一方
は離れたベクトルになります。
つまりAIは「意味の近さ」を数値の距離として扱っています。
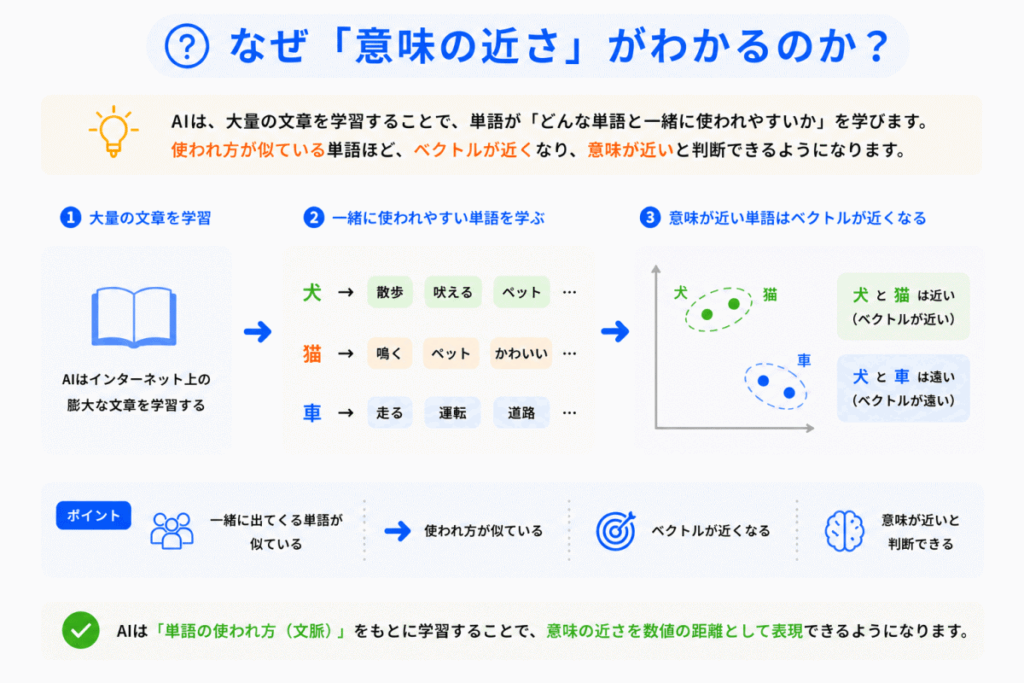
AIは大量文章を学習することで「一緒に使われやすい単語」を学習します。
例えば
のように「似た場面で登場する単語」は近いベクトルになります。
これが「分散表現」の考え方です。
つまり「使われ方が似ている → 意味も近い」という考え方です。
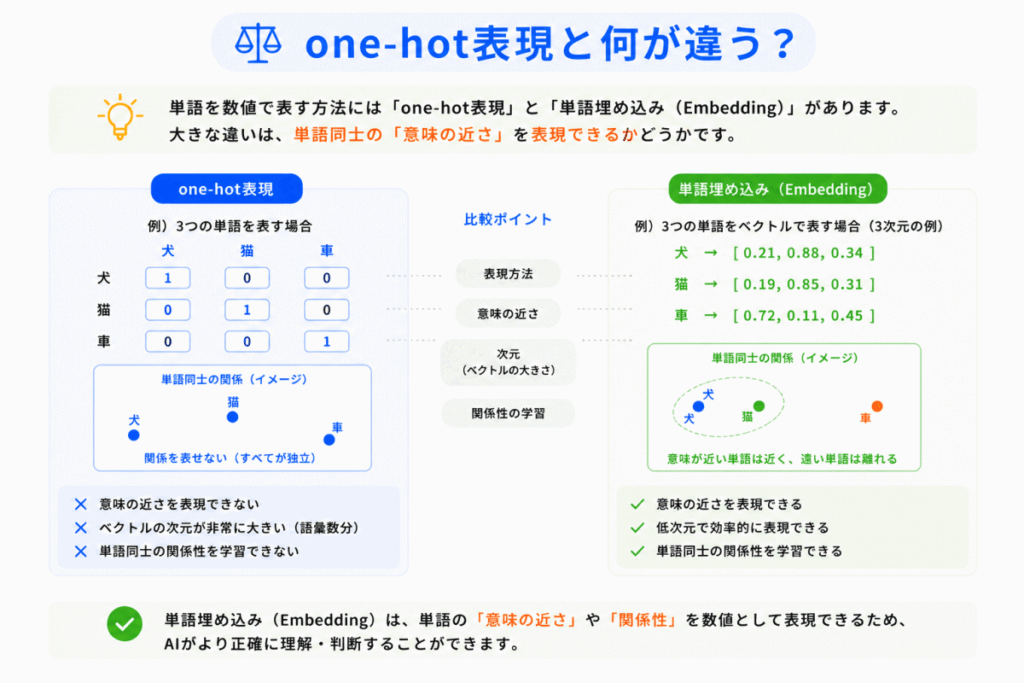
G検定では、ここが非常に重要です。
昔は one-hot表現 が使われていました。
しかし、one-hot表現は
という問題がありました。
一方、単語埋め込みでは
という改善があります。
つまり「意味を持った数値表現」になったことが大きな進化です。
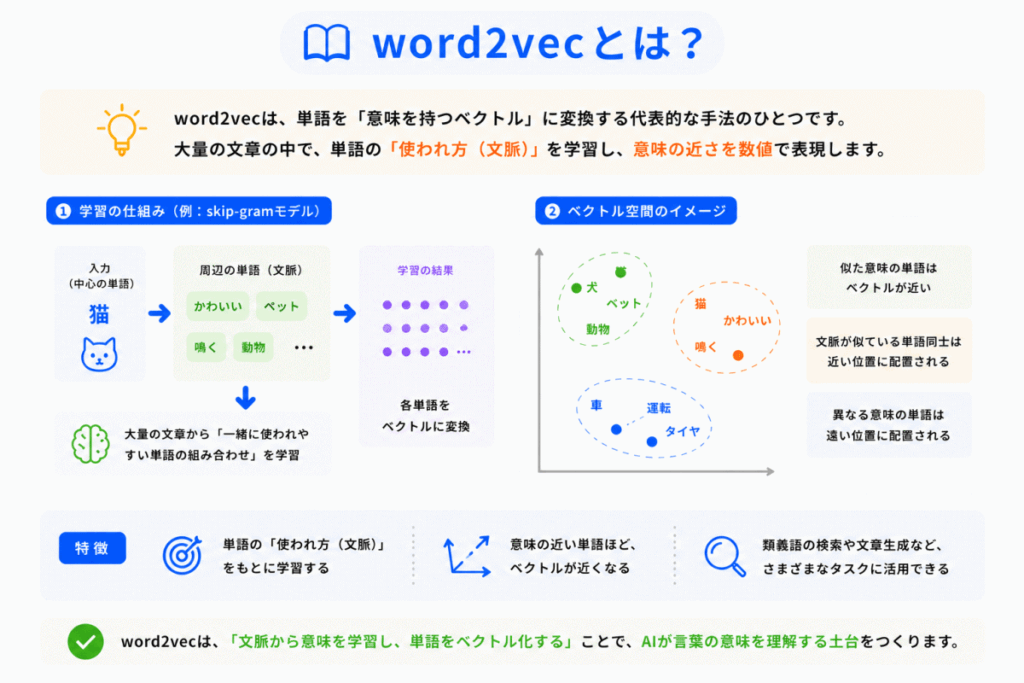
word2vecは「単語埋め込みを学習する代表的技術」です。
Googleが提案した技術で
という方式があります。
どちらも「単語の使われ方」を学習することで、意味の近い単語を近いベクトルへ変換します。
これまで記載してきましたが、単語を数理化する方法として下記のものがあります。


Attentionでは「どの単語を重要視するか」を計算します。
しかし、その前提として「単語がベクトル化されている」必要があります。
つまり
という流れです。
単語埋め込みがなければ「単語同士の関係計算」ができません。
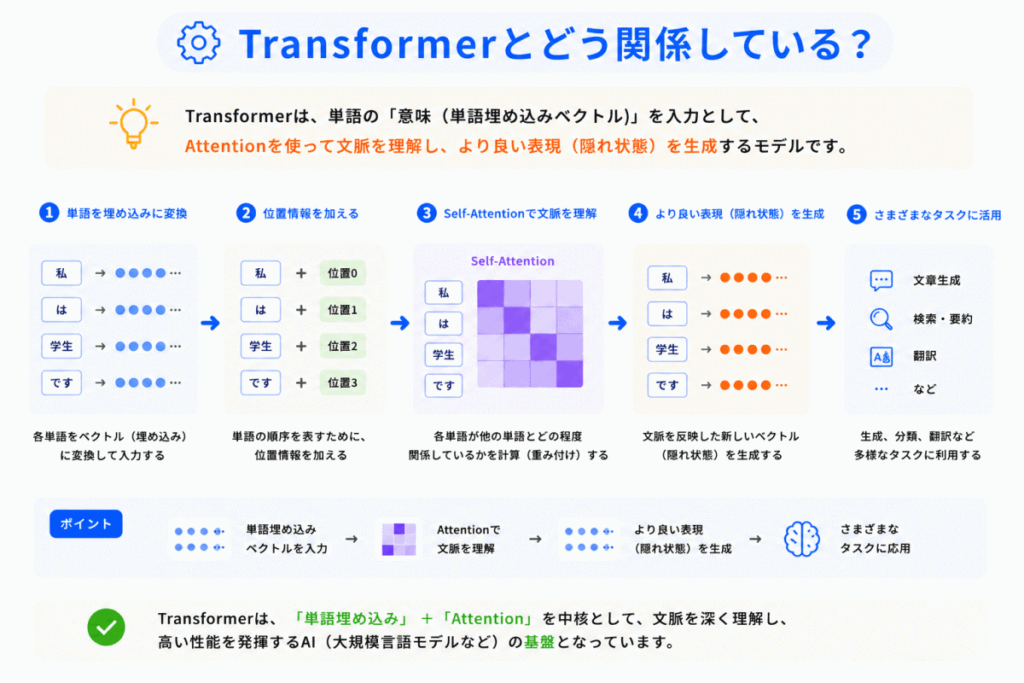
Transformerは「ベクトル化された全トークン」を同時に処理します。
ここで重要なのが「Embeddingされた情報」です。
Transformerは文字ではなく「ベクトル」を処理しています。
つまり、単語埋め込みは「Transformerの入力部分」として重要です。

GPTも「Embeddingされたトークン」を使っています。
流れとしては
です。
つまりGPTは「Embeddingされた意味情報」を使いながら文章生成しています。
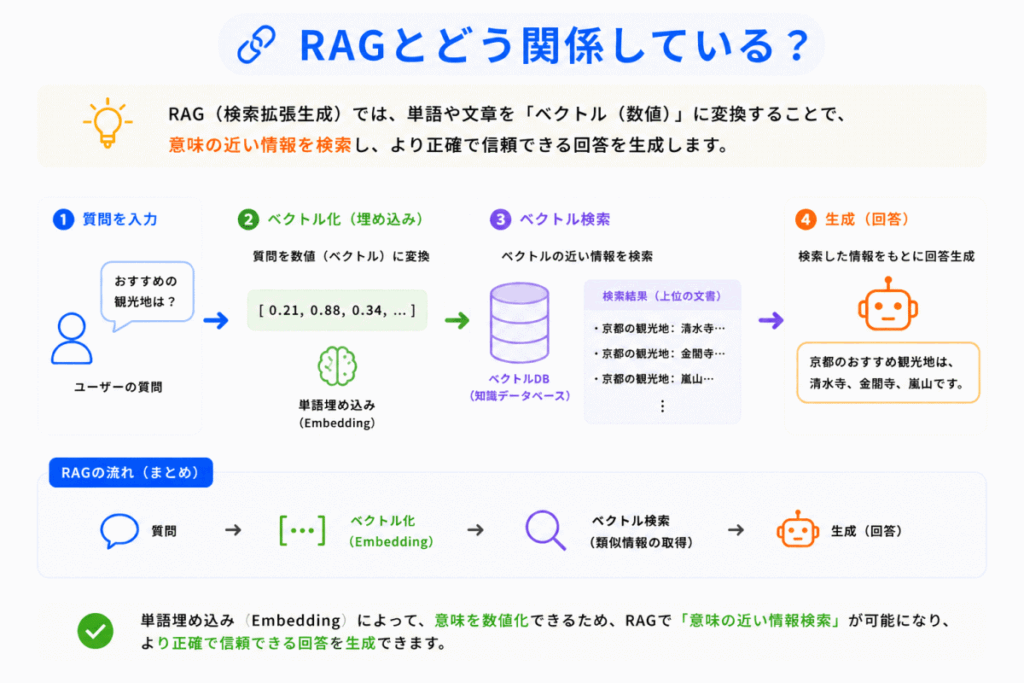
RAGでは「ベクトル検索」が重要です。
例えば
という流れになります。
つまりRAGは「意味の近さ検索」を行っています。
ここでも単語埋め込みの考え方が重要になります。
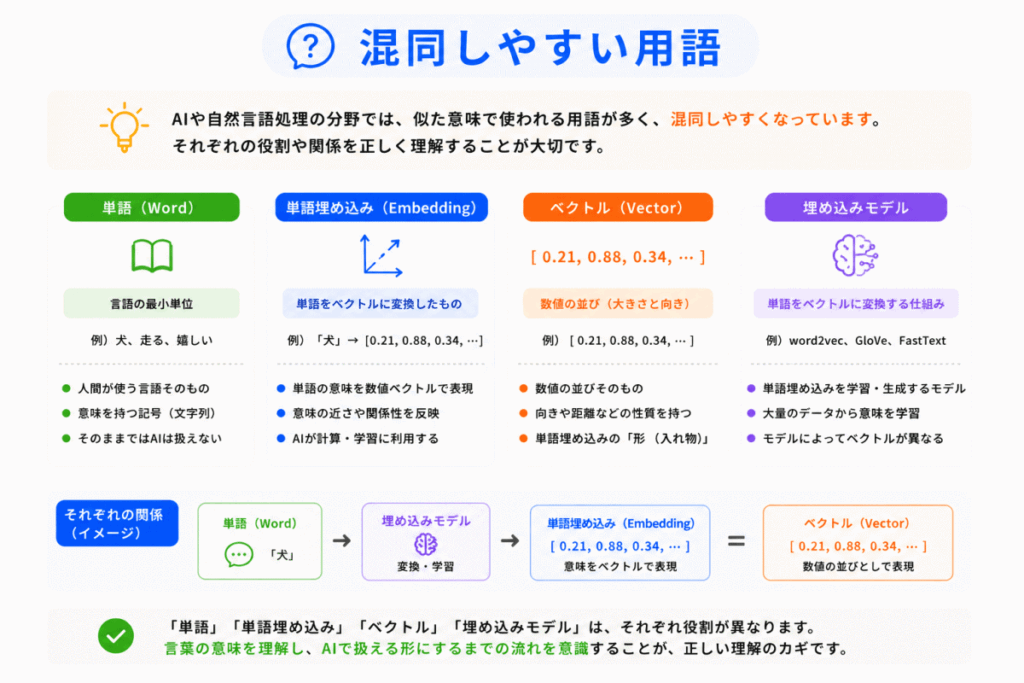
混同しやすい理由は
がすべて近い場所で使われるからです。
整理すると
文章を小さく分割した単位
トークンを意味ある数値へ変換
変換後の数値データ
意味の近さを持ったベクトル表現
という関係です。
G検定では
が問われやすいです。
特に重要なのは「なぜ単語埋め込みが必要だったのか?」です。
単なる暗記ではなく「AIが意味を扱うため」という流れで理解すると、問い方変更にも強くなります。
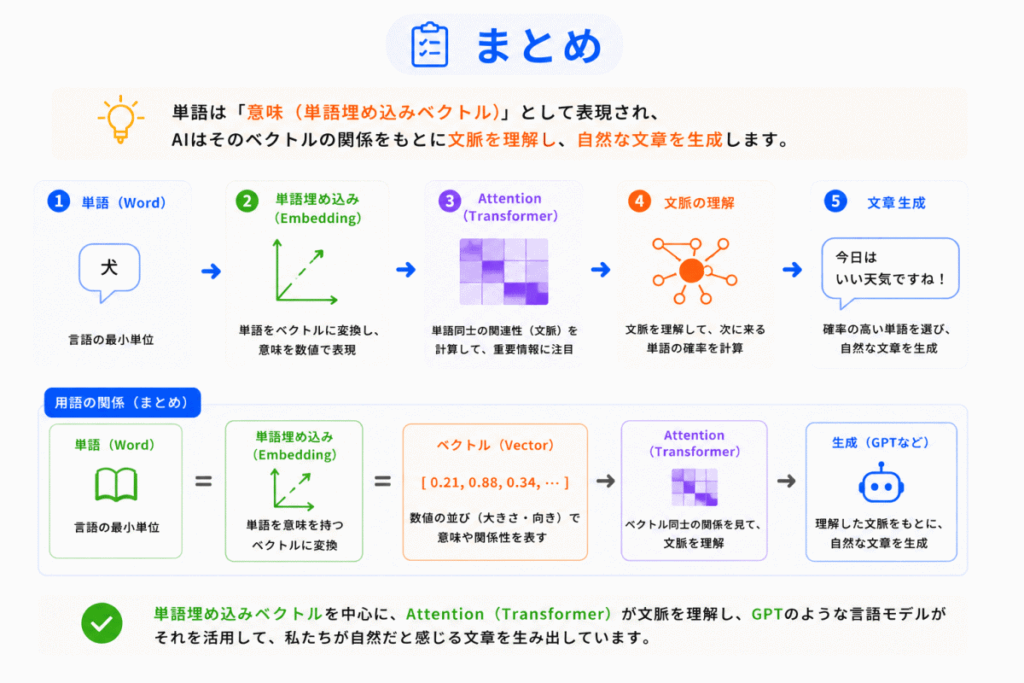
単語埋め込み(Embedding)は「単語を意味のある数値へ変換する技術」です。
現在の生成AIでは
という流れで動いています。
つまりEmbeddingは「生成AI理解の土台」とも言える重要技術です。
G検定では
などが問われますが、本質は「AIは意味を数値として扱っている」という点です。
ここを理解できると、Transformer・GPT・RAGの理解もかなり深まります。
単語埋め込みを理解するには、トークン化、Attention、Transformer、GPTとのつながりをあわせて整理しておくと理解しやすくなります。
関連用語をまとめて確認したい場合は、AI用語一覧も役立ちます。
| おすすめ記事 | 確認できる内容 |
|---|---|
| トークンとは? | 文章の分割単位/トークン化/次トークン予測 |
| Attentionとは? | 重要な情報の確認/単語同士の関係/Transformerとの関係 |
| Transformerとは? | Attention/文脈理解/文章生成が得意な理由 |
| GPTとは? | Transformerとの関係/次トークン予測/文章生成の仕組み |
| AI用語一覧 | AI用語の意味/違い/見分け方 |
| G検定に落ちた原因 | 不合格体験談/暗記学習の失敗/理解重視の勉強法 |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。