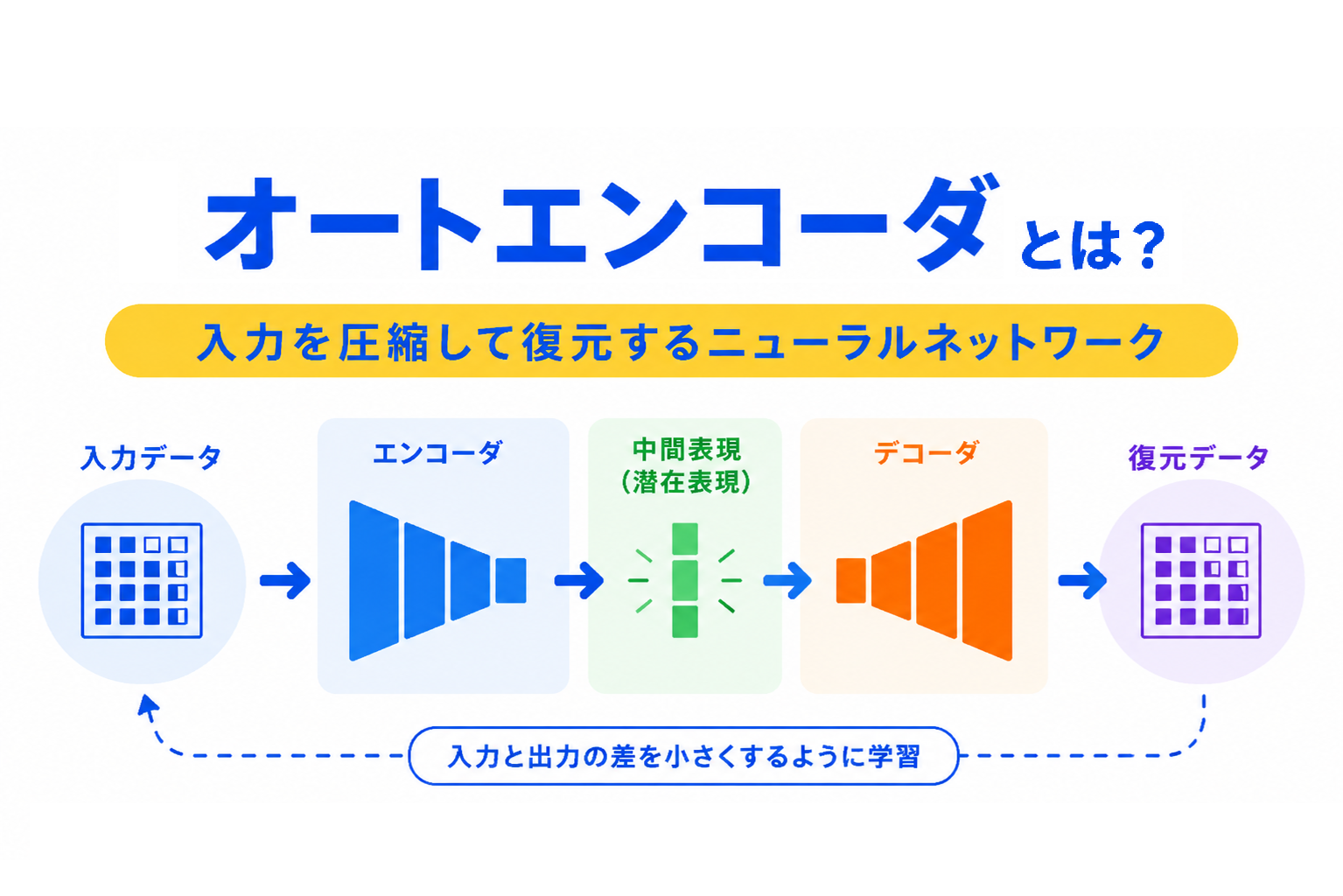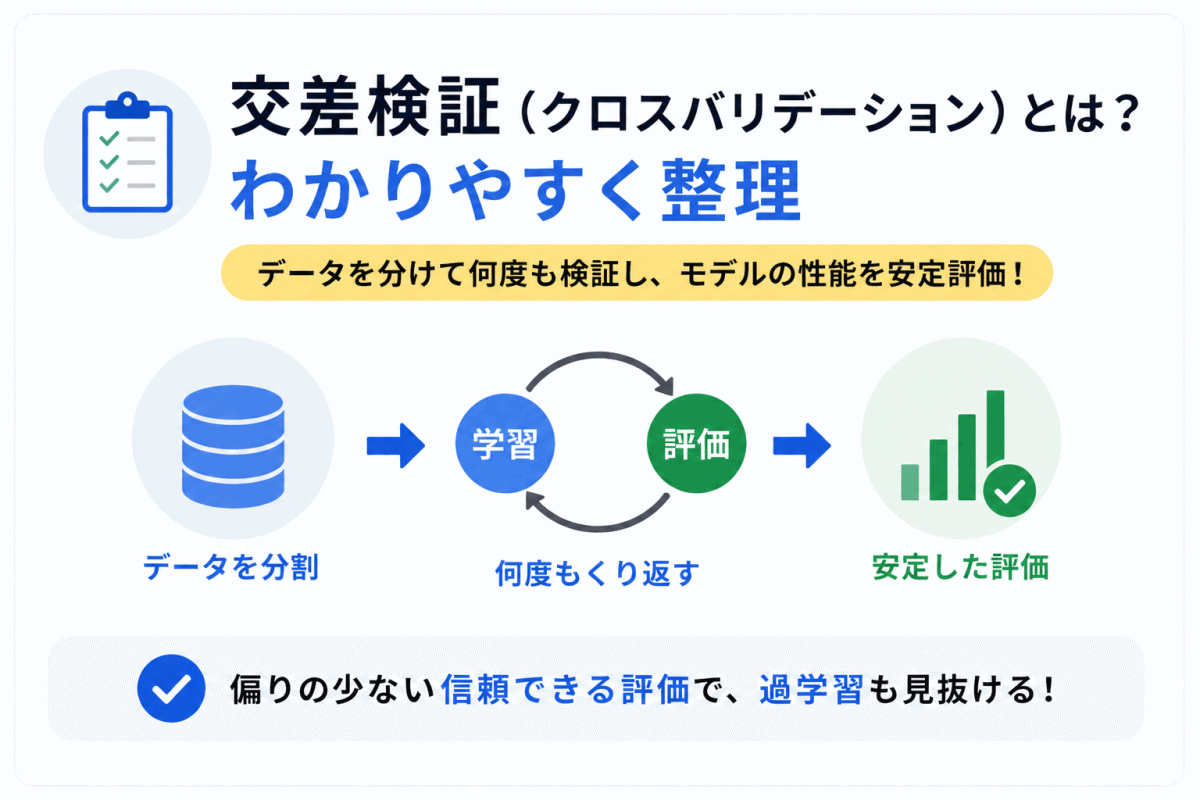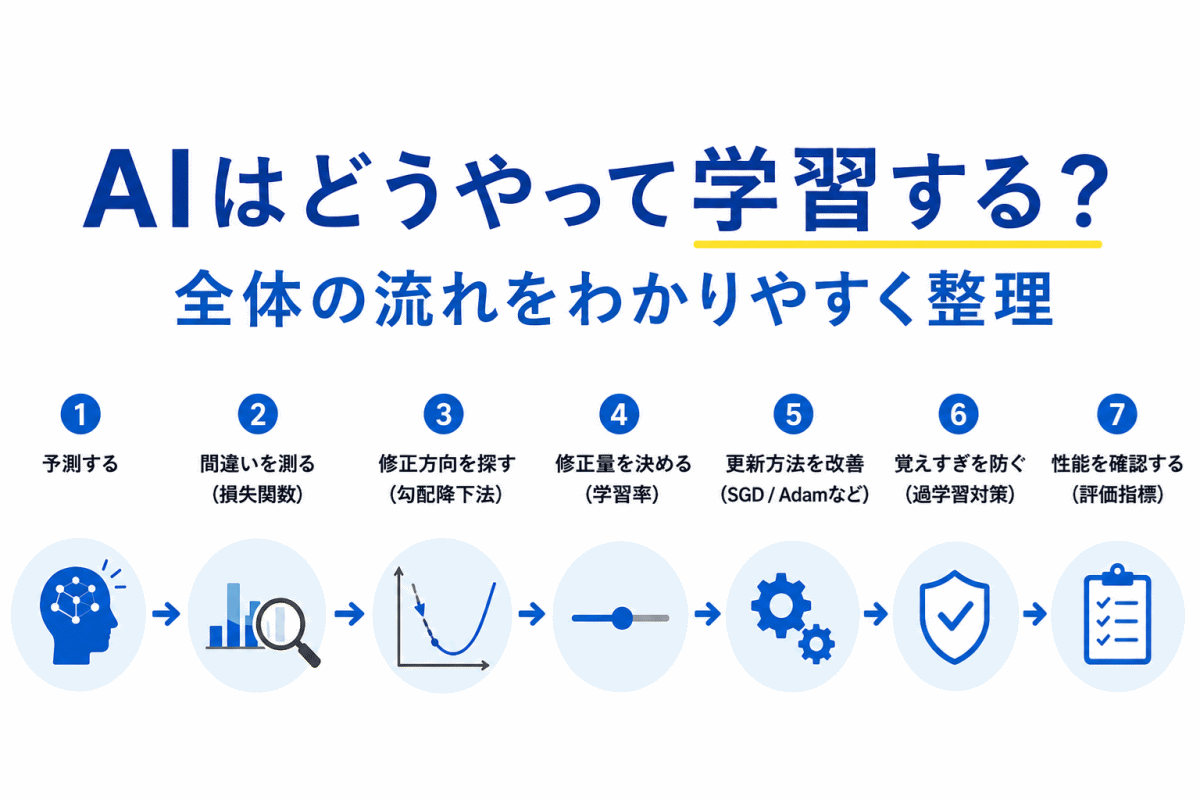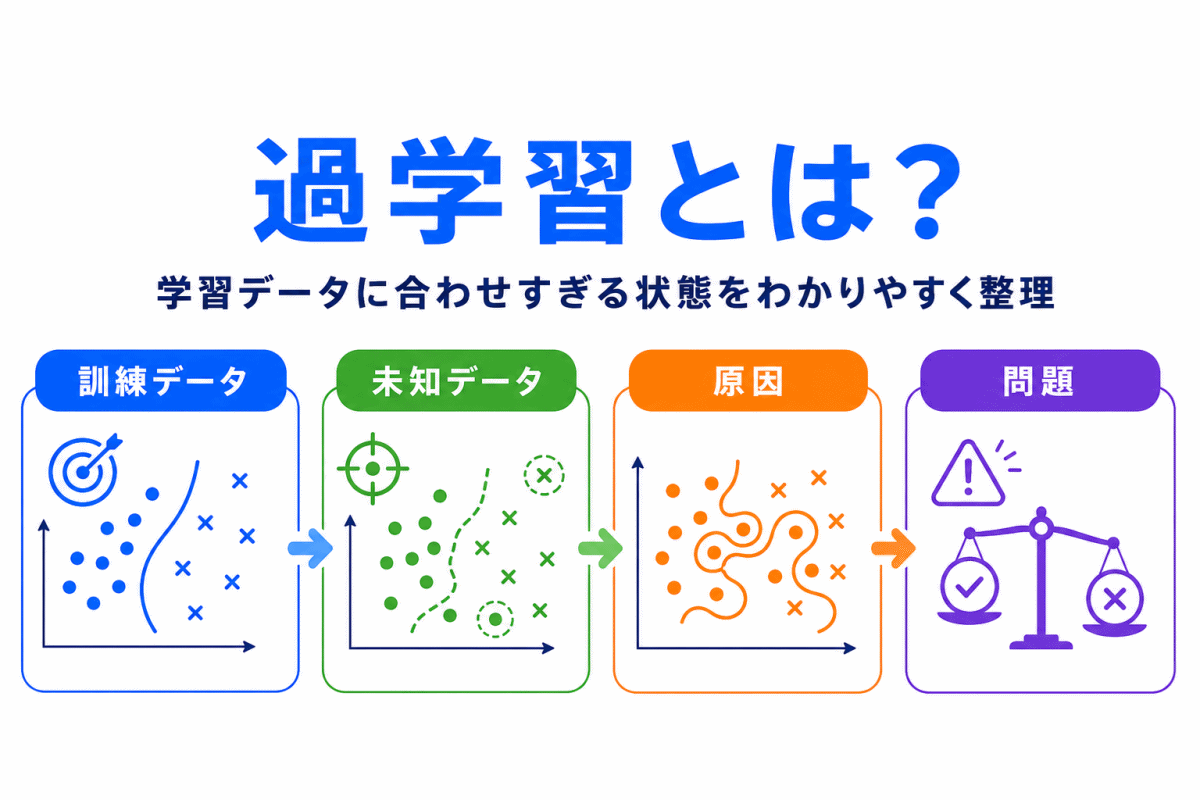
【G検定対策】過学習とは?わかりやすく整理
seo-webmaster
SEO・ウェブマスターブログ
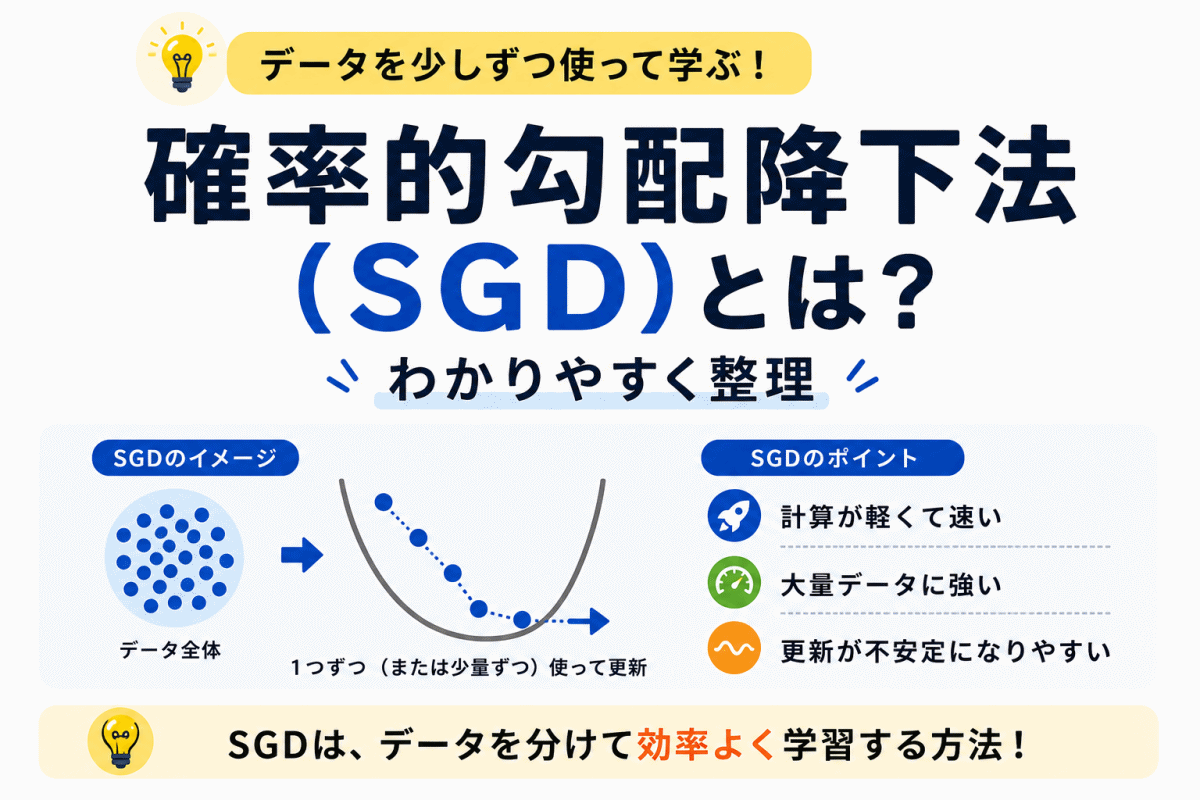
確率的勾配降下法(SGD)は、AIが学習するときに使われる最適化手法のひとつです。
勾配降下法では、損失が小さくなる方向へ重みなどのパラメータを更新します。ただし、すべてのデータを毎回使って更新すると、データ量が多い場合に計算が重くなります。
そこで、データの一部を使って少しずつ更新する方法として登場するのがSGDです。
この記事では、通常の勾配降下法との違い、ミニバッチ学習との関係、Adamとのつながりまで整理します。
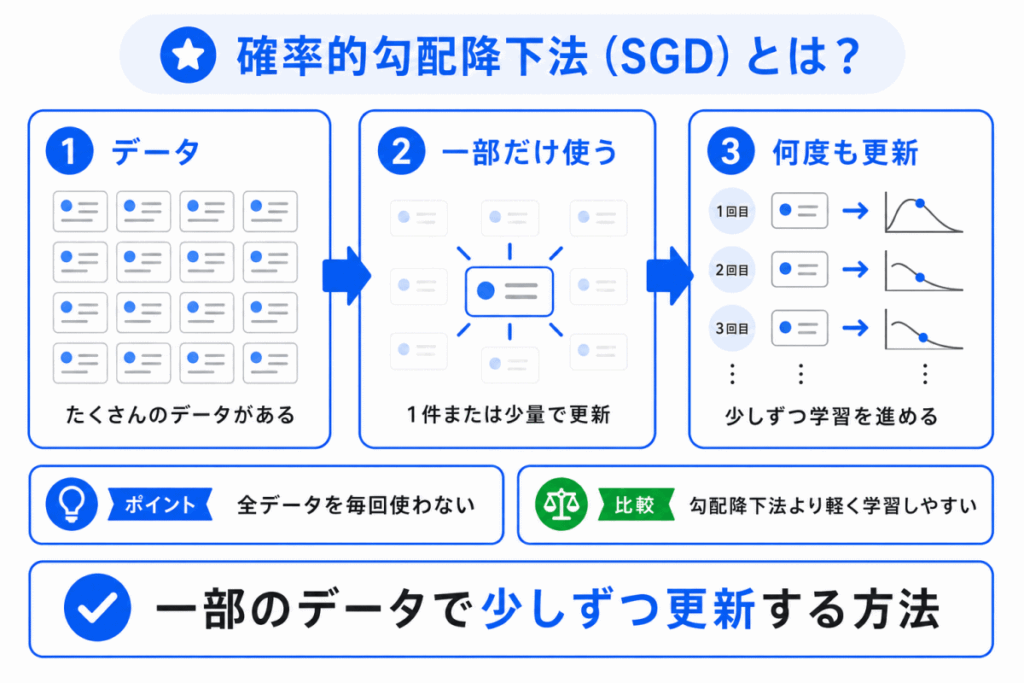
確率的勾配降下法(SGD)とは、データを1件または一部ずつ使って、損失が小さくなるように重みを更新する方法です。
通常の勾配降下法は、すべてのデータを使って更新します。
一方、SGDはすべてのデータを毎回使うのではなく、一部のデータを使って更新します。
| 方法 | 更新に使うデータ | 一言でいうと |
|---|---|---|
| 勾配降下法 | 全データ | 全体を見て更新する |
| SGD | 1件または一部のデータ | 少しずつ更新する |
| ミニバッチ学習 | 小さなまとまりのデータ | 小グループで更新する |
SGDのポイントは、全データを毎回使わず、少しずつ更新することです。
データ量が多い場合でも、1回ごとの計算を軽くしやすいため、大規模な学習で重要になります。
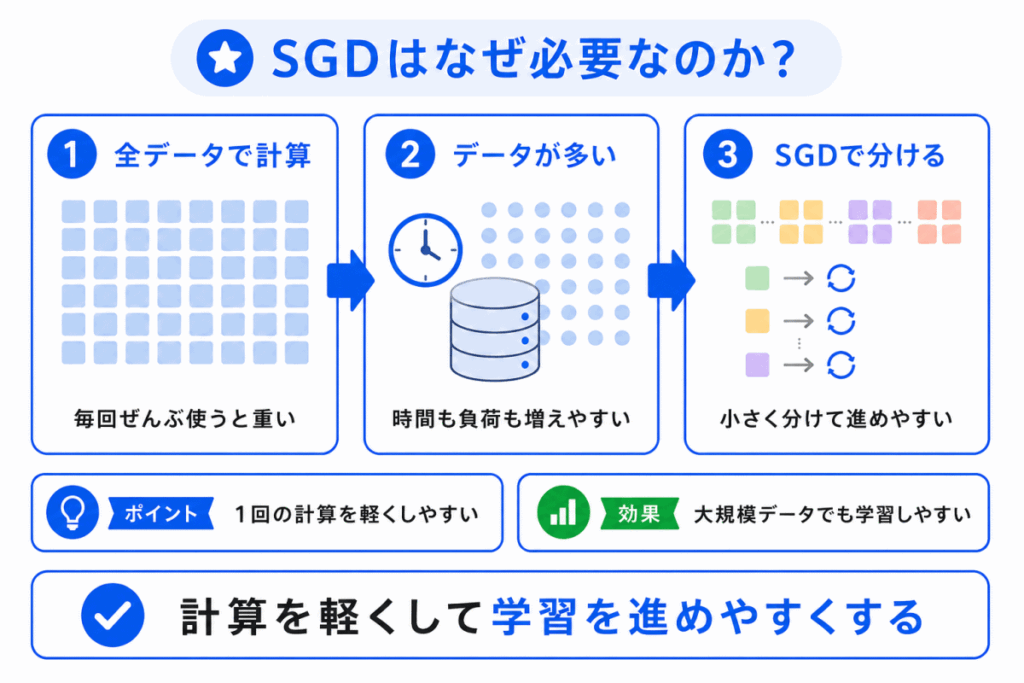
SGDが必要なのは、すべてのデータを毎回使って学習すると、計算が重くなりやすいからです。
AIの学習では、予測と正解のズレを損失関数で計算し、その損失が小さくなるように重みを更新します。
しかし、データが大量にある場合、毎回すべてのデータを使って損失を計算すると時間がかかります。
| 状態 | 起きやすいこと |
|---|---|
| 全データを毎回使う | 計算が重くなりやすい |
| 一部のデータを使う | 1回の更新が軽くなりやすい |
| 少しずつ更新する | 大規模データでも学習を進めやすい |
SGDは、毎回すべてを見てから更新するのではなく、データを少しずつ使って更新します。
そのため、計算を軽くしながら学習を進めやすくなります。
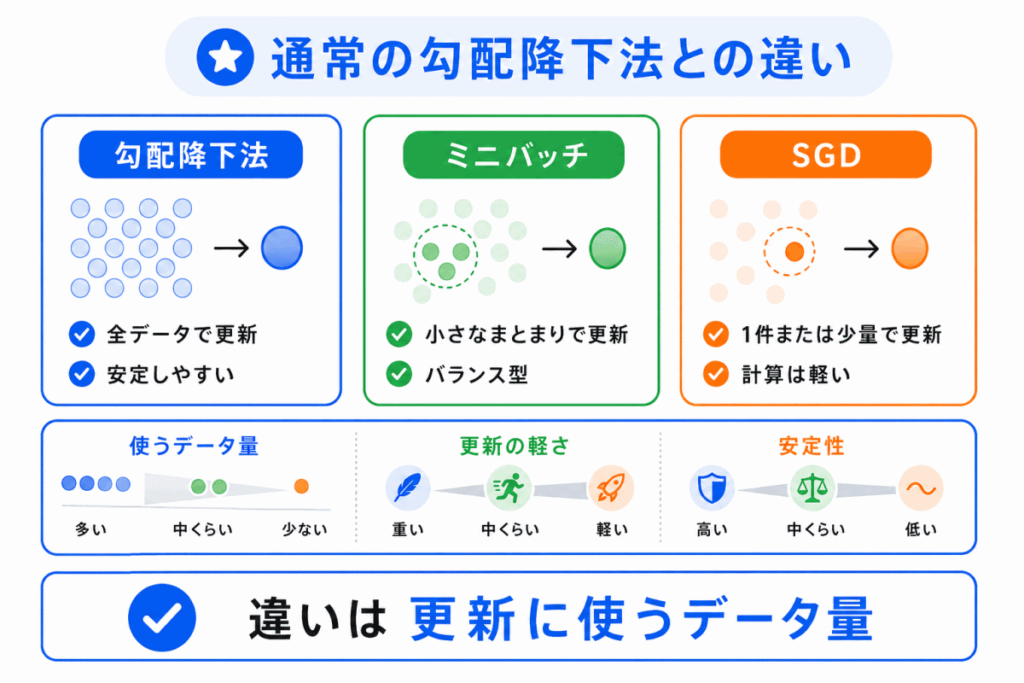
通常の勾配降下法とSGDの違いは、重みを更新するときに使うデータ量です。
通常の勾配降下法では、すべてのデータを使って勾配を計算し、重みを更新します。
SGDでは、1件または一部のデータを使って勾配を計算し、重みを更新します。
| 比較 | 勾配降下法 | SGD |
|---|---|---|
| 使うデータ | 全データ | 1件または一部 |
| 1回の計算 | 重くなりやすい | 軽くしやすい |
| 更新の安定性 | 安定しやすい | 揺れやすい |
| 大規模データ | 計算が大変になりやすい | 対応しやすい |
イメージとしては、通常の勾配降下法は「全員の意見を聞いてから1回更新する」方法です。
一方、SGDは「一部の意見を聞きながら、こまめに更新する」方法です。
そのため、SGDは速く動きやすい反面、更新が少し不安定になりやすい特徴があります。
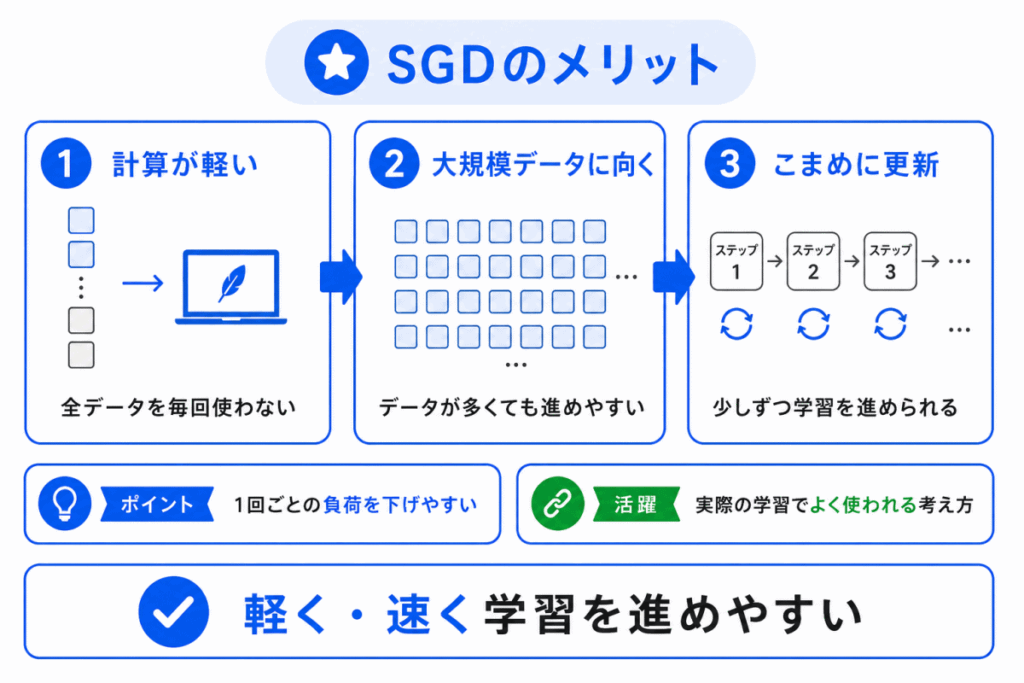
SGDのメリットは、計算を軽くしやすいことです。
全データを毎回使わないため、1回あたりの更新にかかる計算量を抑えやすくなります。
| メリット | 内容 |
|---|---|
| 計算が軽い | 全データを毎回使わない |
| 大規模データに向く | データが多くても学習を進めやすい |
| 更新回数を増やしやすい | 少しずつこまめに更新できる |
| メモリ使用量を抑えやすい | 一度に扱うデータが少ない |
データが多いほど、全データを毎回使う方法は負担が大きくなります。
SGDは、一部のデータを使ってこまめに更新できるため、大規模な学習で使いやすい方法です。
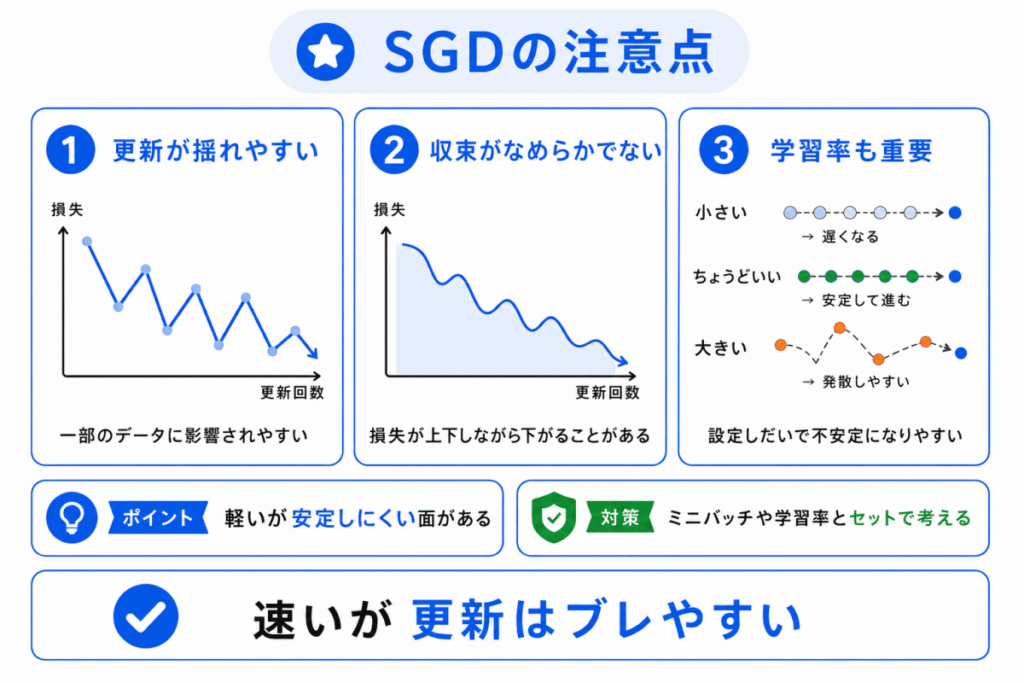
SGDにはメリットがある一方で、注意点もあります。
一部のデータだけを使って更新するため、毎回の更新方向が安定しにくいことがあります。
| 注意点 | 内容 |
|---|---|
| 更新が揺れやすい | 一部のデータに影響されやすい |
| 収束が滑らかでない | 損失が上下しながら下がることがある |
| 学習率の影響を受ける | 学習率が大きすぎると不安定になりやすい |
| 結果がばらつくことがある | データの選び方に影響されることがある |
SGDは、少しずつ更新できる便利な方法です。
ただし、全体を毎回見ているわけではないため、更新がブレることがあります。
そのため、SGDは学習率やミニバッチ学習とセットで理解すると分かりやすくなります。
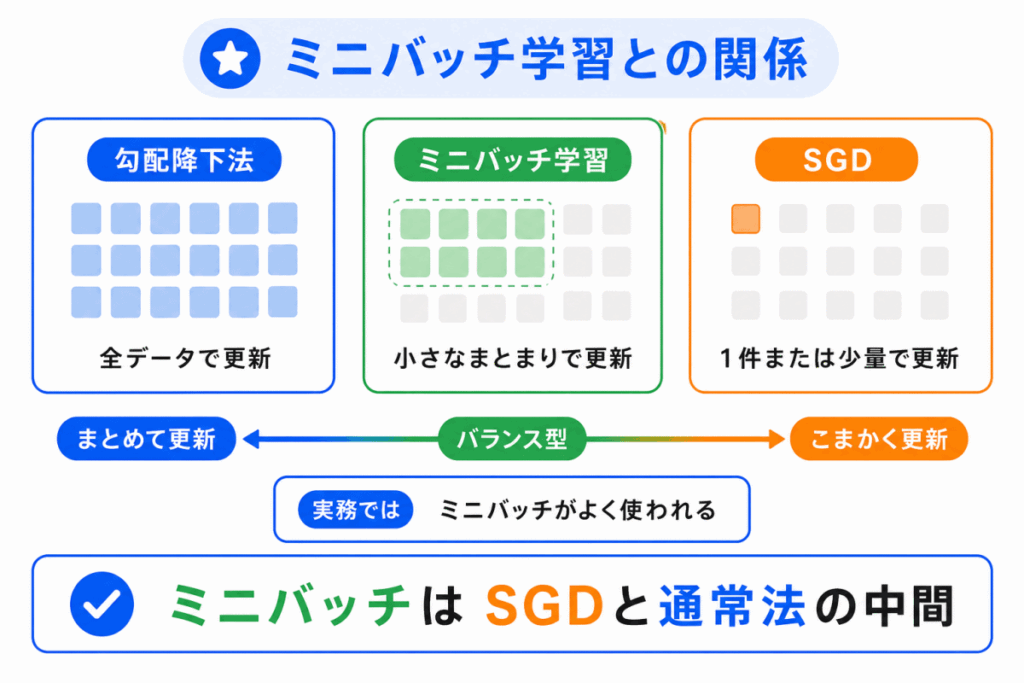
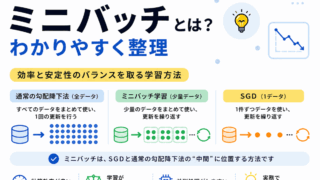
ミニバッチ学習は、SGDと通常の勾配降下法の中間のような考え方です。
1件だけではなく、データを小さなまとまりに分けて、そのまとまりごとに重みを更新します。
| 方法 | 使うデータ量 | イメージ |
|---|---|---|
| 勾配降下法 | 全データ | まとめて更新 |
| SGD | 1件または一部 | かなり小さく更新 |
| ミニバッチ学習 | 小さなまとまり | 小グループで更新 |
実際のディープラーニングでは、完全に1件ずつ更新するSGDよりも、ミニバッチ学習が使われることが多いです。
ミニバッチ学習では、計算の軽さと更新の安定性のバランスを取りやすくなります。
つまり、SGDを理解するときは、全データ・1件・小さなまとまりの違いで整理すると分かりやすいです。
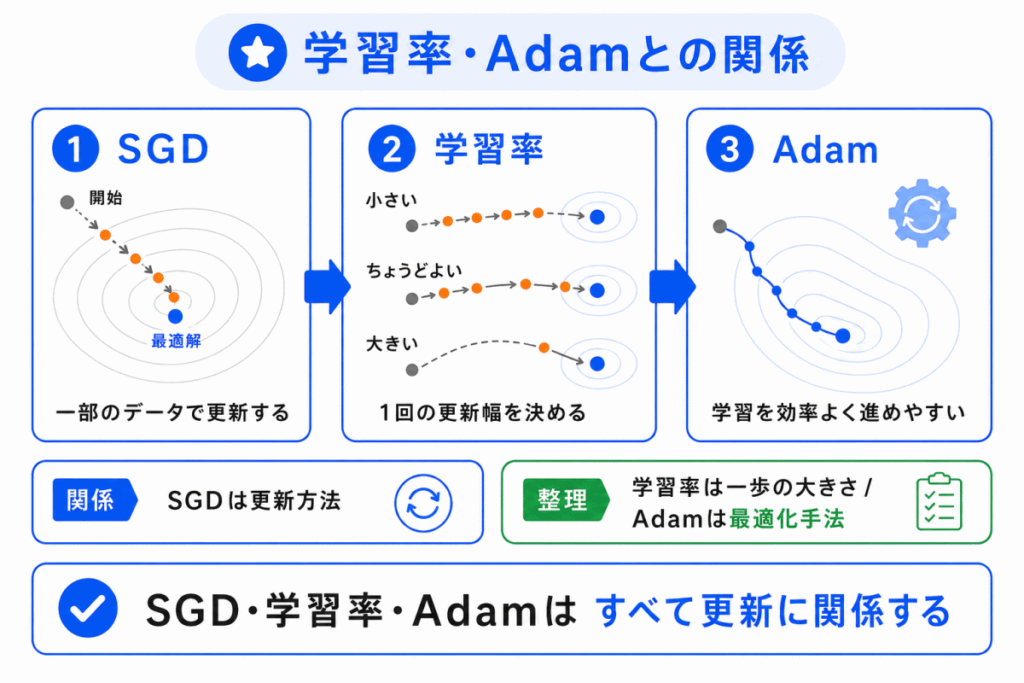
SGDは、学習率とも深く関係します。
SGDでは、損失が小さくなる方向へ重みを更新しますが、どれくらい大きく更新するかは学習率によって決まります。
| 用語 | 一言でいうと |
|---|---|
| 勾配降下法 | 損失が小さくなる方向へ進む基本の考え方 |
| SGD | 一部のデータを使って更新する方法 |
| 学習率 | 更新の一歩の大きさを決める値 |
| Adam | 効率よく学習しやすくする最適化手法 |
Adamは、SGDよりも効率よく学習を進めるために使われる代表的な最適化手法です。
G検定対策では、細かい数式よりも、次のように整理すると十分です。
どちらも、損失を小さくするための重み更新に関係します。
G検定では、SGDは勾配降下法・ミニバッチ学習・Adamとセットで問われやすいです。
| 問われやすい内容 | 押さえるポイント |
|---|---|
| SGDの意味 | 一部のデータを使って重みを更新する |
| 通常の勾配降下法との違い | 全データを使うか、一部を使うか |
| ミニバッチ学習との関係 | 小さなまとまりのデータを使う |
| SGDのメリット | 計算を軽くしやすい |
| SGDの注意点 | 更新が不安定になりやすい |
| Adamとの関係 | どちらも最適化手法に関係する |
特に注意したいのは、次のような誤解です。
| 誤解しやすい表現 | 正しい整理 |
|---|---|
| SGDは全データを毎回使う | SGDは一部のデータを使って更新する |
| SGDは必ず安定して学習できる | 更新が揺れやすいことがある |
| ミニバッチ学習とSGDは完全に無関係 | どちらも一部のデータを使う考え方 |
| Adamは損失関数そのもの | Adamは最適化手法 |
問題文で
といった表現が出てきたら、SGDや最適化手法との関係を意識すると整理しやすくなります。
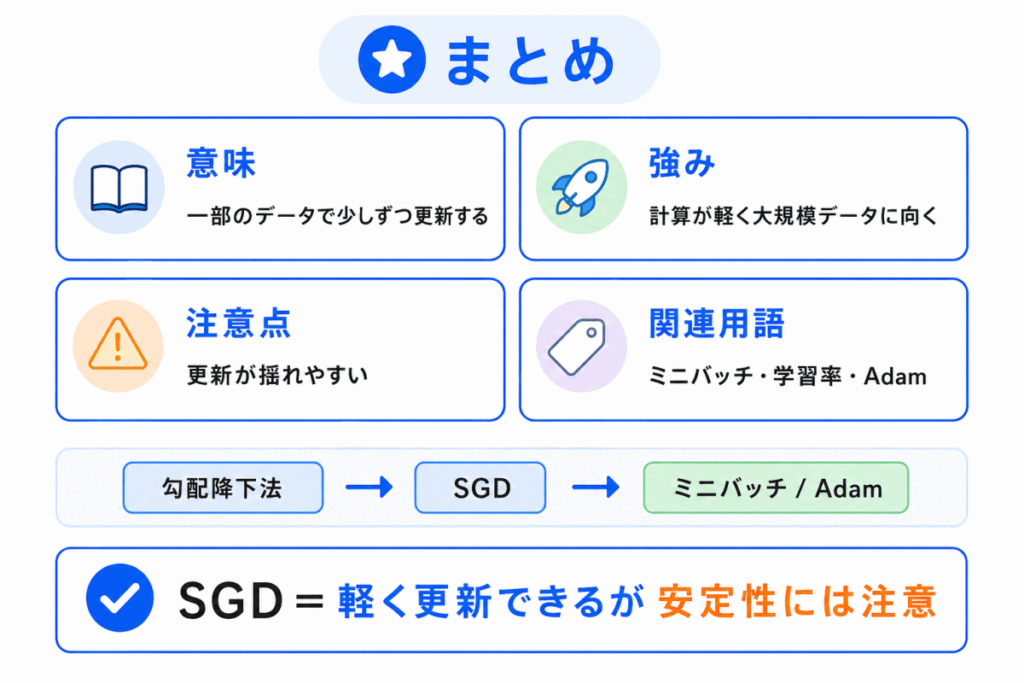
確率的勾配降下法(SGD)とは、データを1件または一部ずつ使って、損失が小さくなるように重みを更新する方法です。
通常の勾配降下法は全データを使って更新しますが、SGDは一部のデータを使って少しずつ更新します。
そのため、計算を軽くしやすく、大規模データでも学習を進めやすいというメリットがあります。
一方で、一部のデータに影響されるため、更新が揺れやすいという注意点もあります。
最後に整理すると、次のようになります。
| 用語 | 一言でいうと |
|---|---|
| 勾配降下法 | 全データを使って更新する基本的な考え方 |
| SGD | 1件または一部のデータを使って更新する方法 |
| ミニバッチ学習 | 小さなまとまりのデータを使って更新する方法 |
| 学習率 | 更新の一歩の大きさを決める値 |
| Adam | 効率よく学習しやすくする最適化手法 |
G検定では、SGDを単独で覚えるよりも、勾配降下法・ミニバッチ学習・学習率・Adamとつなげて理解しておくことが大切です。
この記事とあわせて読むなら、以下の記事がおすすめです。
SGDは勾配降下法の考え方をもとにした学習方法です。
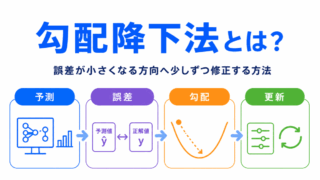
SGDでは、重みをどれくらい更新するかを決める学習率が重要になります。

SGDとミニバッチ学習は混同しやすいので、違いをあわせて確認しておくと安心です。
SGDとAdamはどちらも最適化手法として問われやすいため、違いを整理しておくと理解しやすくなります。
重要用語をチェックシートとしてまとめました。

用語の意味をまとめて確認したい場合は、G検定で覚えたいAI用語一覧もあわせて読んでみてください。

1回目不合格でした。不合格だった原因を分析しました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認